push_back 과 emplace_back 둘 다 실질적으로 수행하는 일은 “컨테이너의 끝에 요소를 추가하는것” 로 동일하다. 하지만 두 함수를 memory allocation 관점에서 보면 emplace_back 이 훨씬 효율적으로 작동한다.
push_back 이 호출될 때 객체 관점에서 순서는 다음과 같다.
- Stack 영역에 생성자를 호출 하면서 임시객체(temporary object)가 할당 된다.
- 복사 생성자(copy constructor) 혹은 이동 생성자 통해 함수 안에서 또 하나의 temporay object를 생성한다.
- 생성된 temporary object를 벡터 컨테이너의 끝에 추가한다.
- 1번의 임시객체가 소멸된다.
이렇게, push_back 함수는 “객체” 자체를 집어넣는 방식으로, R-value의 임시객체가 필요하다. 단순히 하나의 객체를 추가하는 단순한 연산임에도 불구하고, 객체의 생성과 파괴가 한번 이루어진다.
그에 반해서, emplace_back 는 direct하게 함수 내에서 임시객체를 생성과 이동을 통해 element를 생성한다. 다시말해, 불필요한 임시객체의 생성과 파괴 과정없이 효율적으로 벡터 element를 추가한다.
Example
#include <chrono>
#include <iostream>
#include <string>
#include <vector>
class Foo {
public:
Foo() = default;
Foo(const std::string name, const int age) : m_name(name), m_age(age) {
std::cout << "Foo()" << std::endl;
}
// declare copy constructor explicitly
Foo(const Foo& rhs) : m_name(rhs.m_name), m_age(rhs.m_age) {
std::cout << "Foo() copy" << std::endl;
}
// declare move constructor explicitly
Foo(const Foo&& rhs) : m_name(rhs.m_name), m_age(rhs.m_age) {
std::cout << "Foo() move" << std::endl;
}
~Foo() {
std::cout << "~Foo()" << std::endl;
}
private:
std::string m_name;
int m_age;
};
int main(int argc, char* argv[]) {
std::vector<Foo> foovec;
foovec.reserve(2);
std::cout << "emplace back" << std::endl;
foovec.emplace_back("tom", 63);
std::cout << "------------------------" << std::endl;
std::cout << "push back" << std::endl;
foovec.push_back(Foo("chris", 44));
std::cout << "------------------------" << std::endl;
return 0;
}
Result
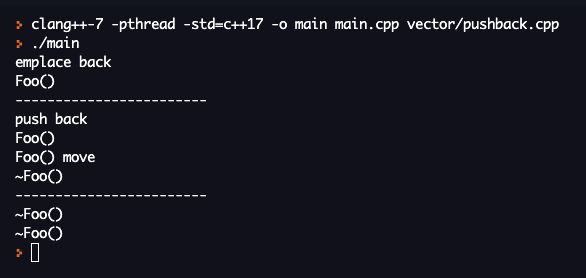
예상했던것처럼, push_back 함수는 객체의 생성, 이동, 소멸이 되었지만, emplace_back 의 경우 객체가 생성만 된것을 확인할 수 있다.
Benchmark
#include <iostream>
#include <chrono>
#include <vector>
#include <string>
int main(int argc, char* argv[]) {
std::vector<Foo> foovec;
std::size_t count = std::atoi(argv[2]);
foovec.reserve(count);
if (argv[1] == std::string("push_back")) {
auto t1 = std::chrono::high_resolution_clock::now();
for (std::size_t idx = 0; idx < count; idx++) {
foovec.push_back(Foo("blank", 1));
}
auto t2 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> fp_ms = t2 - t1;
std::cout << "duration : " << fp_ms.count() << std::endl;
} else if (argv[1] == std::string("emplace_back")) {
auto t1 = std::chrono::high_resolution_clock::now();
for (std::size_t idx = 0; idx < count; idx++) {
foovec.emplace_back("blank", 1);
}
auto t2 = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> fp_ms = t2 - t1;
std::cout << "duration : " << fp_ms.count() << std::endl;
}
return 0;
}
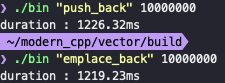
1000만개의 elements를 추가하는 간단한 벤치마킹 코드를 돌려봤을때, emplace_back이 push_back보다 약 7ms정도 미세하게 빠르다는것을 확인할 수 있었다.
push_back 을 언제 사용해야하는가
그렇다면, 모든 push_back 을 emplace_back으로 바꾸면 되는것일까? 라고 생각이 들 수 있다. 하지만 아래의 또 다른 예제를 보면 그렇지 않다는것을 알 수 있다.
v.push_back(10000);
v.emplace_back(10000);
위의 코드만 봤을때, push_back의 경우 명확하다. 숫자 10000을 vector에 추가한다는것을 나타내지만, emplace_back의 경우 확실히 알 수 없다.
만약 vector가 std::vector<std::vector<int>> 의 형태인 경우, 10000개의 요소를 메모리에 할당하게 된다. push_back을 사용했을 경우 compile error를 통해 compile 시점에 개발자가 인지하고 고칠 수 있지만, emplace_back의 경우 개발자가 의도하지 않은 결과를 초래하게 될 수도 있다.
결론
위의 벤치마크 코드에서도 확인하였듯이 추가해야 할 element 객체의 크기가 엄청 큰 경우 혹은 performance critical한 경우가 아니라면, 명시적인 타입의 push_back을 사용하여 explicit하고, safety한 코드를 작성하는것도 하나의 방법이라고 생각한다.